

Concept-based explanations of machine learning applications have a greater intuitive appeal, as established by emerging research as an alternative to traditional approaches. Concept-driven methods explain the decisions of a model by aligning its representation with human understandable concepts. Conventional approaches to ML explainability attribute a model’s behavior to low-level features of the input, whereas concept-based methods examine the high-level features of the image and extract semantic knowledge from it. Further, this semantic information is mapped to the model’s internal processes. This maneuver gives quite a good glimpse into the model’s reasoning process. The efficacy of concept-based methods is assessed with causal effects estimation. It means comparing the outcome by changing various concepts and noting their impact, one at a time. This exercise of sensitivity analysis identifies how altering a specific concept causally influences the model’s predictions. While the causal effect method is gaining prominence, current methods have significant limitations. The existing causal concept effect assumes complete observation of all concepts involved within the dataset, which can fail in practice. In reality, the identification of concepts from data can vary between experts or automated systems, and one or many concepts may only be annotated in part of the dataset. This article discusses the latest research that aims to solve this problem.
Researchers from the University of Wisconsin-Madison propose a framework named “Missingness-aware Causal Concept Explainer “to capture the impact of unobserved concepts in data. They do so by constructing pseudo-concepts that are orthogonal to observed concepts. The authors first perform mathematical experiments to show how unobserved concepts hinder the unbiased estimation of causal explanations.
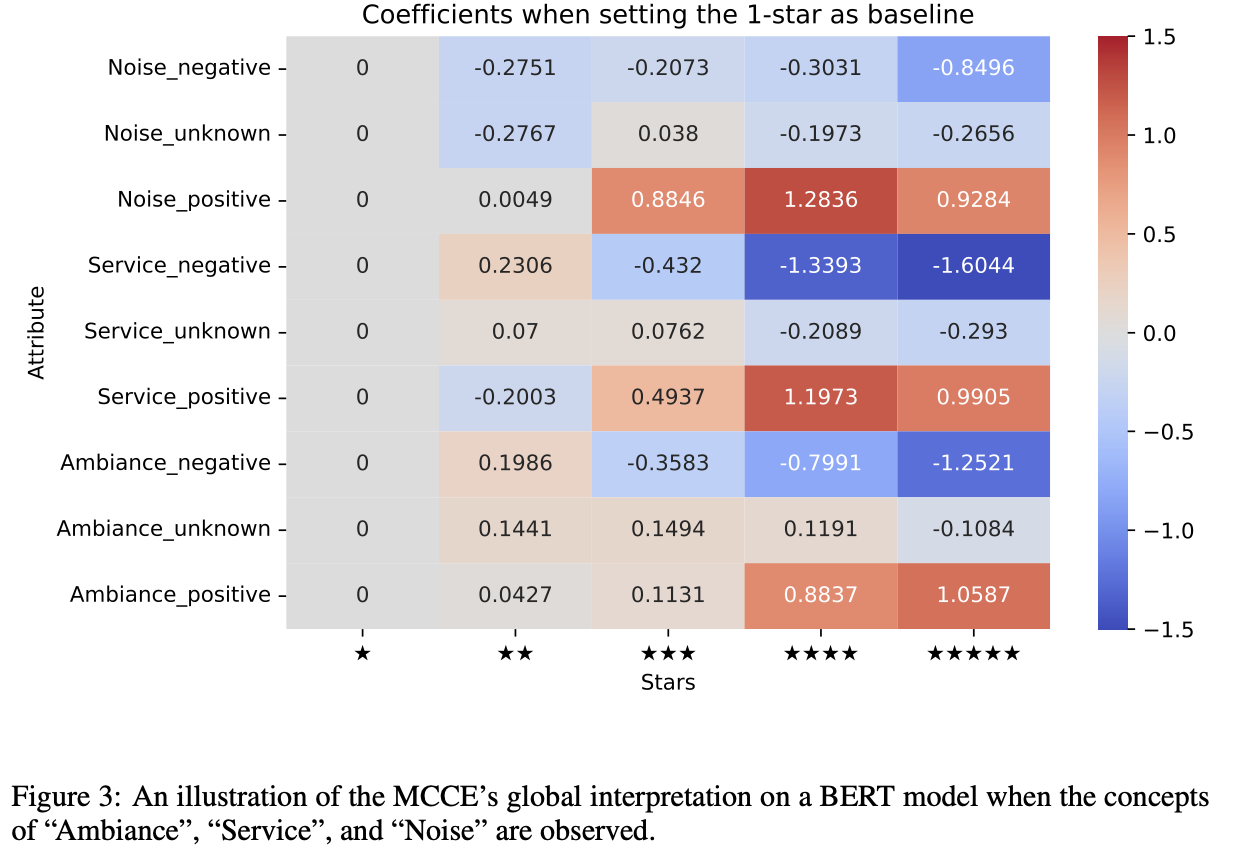
The authors model the relationship between concepts and the model’s output with a linear function. MCCE is multi-capable in determining the individual sample’s effects and generalizing the thought process of neural networks while making a rule. Thus, it explains reasoning at both the individual sample level and the aggregate black box. MCCE’s operational strategy is simple: it compensates for the information missed in observed concepts with the help of raw data. Authors create pseudo-concept vectors orthogonal to observed data using linear transformations from encoded input data. A linear model is then trained on pseudo-concepts collectively with actual concepts.
For the experiment, the authors chose the CEBaB dataset. An interesting and noteworthy fact about this dataset is that it is the only dataset with human-verified approximate counterfactual text. They performed multiclass semantic classification by fine-tuning data on three open Large models – base BERT, base RoBERTa, and Llama-3. The results of the experiments validated this research.MCCE outperformed S-Learner overall in all the metrics, with either one or two unobserved concepts. Further, in a case study, MCCE demonstrated a distinct advantage over the baselines when two of the four concepts were unobserved. Besides the robust performance of the proposed idea, MCCE also showed potential as an interpretable predictor.MCCE predictor achieved comparable performance when leveraging BERT and RoBERTa’s hidden states compared to their black-box model counterpart
This research gave an elegant yet effective solution to the existing problem in causal effects for explainability. While including MCCE in fine-tuning made the performance robust, we could further comment on its accuracy and generalizability after validating more data across domains and classes.
Check out the Paper here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Missingness-aware Causal Concept Explainer: An Elegant Explanation by Researchers to Solve Causal Effect Limitations in Black Box Interpretability appeared first on MarkTechPost.
