

Generative Large Multimodal Models (LMMs), such as LLaVA and Qwen-VL, excel in vision-language (VL) tasks like image captioning and visual question answering (VQA). However, these models face challenges when applied to foundational discriminative VL tasks, such as image classification or multiple-choice VQA, which require discrete label predictions. The primary obstacle is the difficulty in extracting useful features from generative models for discriminative tasks.
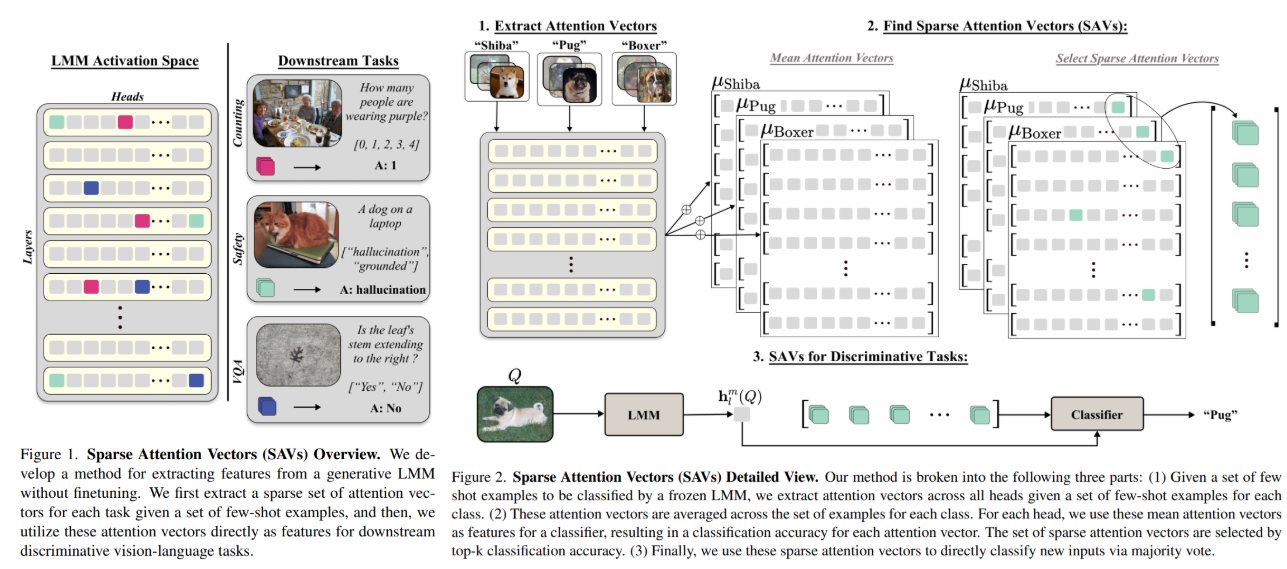
Current methods for adapting LMMs to discriminative tasks often rely on prompt engineering, finetuning, or specialized architectures. Despite their promise, these approaches are limited by their dependency on large-scale trAIning data, modality-specific features, or lack of flexibility. To tackle this problem, a team of researchers from Carnegie Mellon University, University of California, Berkeley, IBM Research, and MIT-IBM Watson AI Lab proposes a novel solution: Sparse Attention Vectors (SAVs). SAVs are a finetuning-free method that leverages sparse attention head activations in LMMs as features for discriminative VL tasks. Inspired by neuroscience’s concept of functional specificity (how different parts of the brain are specific to different functions) and recent work on transformer interpretability, this method uses fewer than 1% of the attention heads to extract discriminative features effectively. SAVs achieve state-of-the-art performance with only few-shot examples and demonstrate robustness across diverse tasks.
Diving deeper into how the method works, the following steps were followed to identify and utilize Sparse Attention Vectors as shown in Figure 2:
- Extracting Attention Vectors: For a frozen LMM and a few-shot labeled dataset (e.g., 20 examples per label), attention vectors are extracted from each attention head in every layer. Specifically, for the final token of each input sequence, the attention vector is computed as an output of the dot-product attention mechanism.
- Identifying Relevant Vectors: The discriminative capability of each attention vector is evaluated using a nearest class centroid classifier. For each class, the mean (centroid) attention vector is computed across the few-shot examples. Cosine similarity is calculated between each input’s attention vector and the class centroids, and attention heads are ranked based on their classification accuracy. The top-performing heads (e.g., the top 20) are selected as the sparse attention vector set (HSAV).
- Classification Using SAVs: Given a query input, predictions are made using the selected sparse attention heads. For each head in HSAV, the query’s similarity to class centroids is computed, and the final class label is determined by a majority vote across all heads. This approach allows the use of less than 1% of the total attention heads, making the method lightweight and efficient.
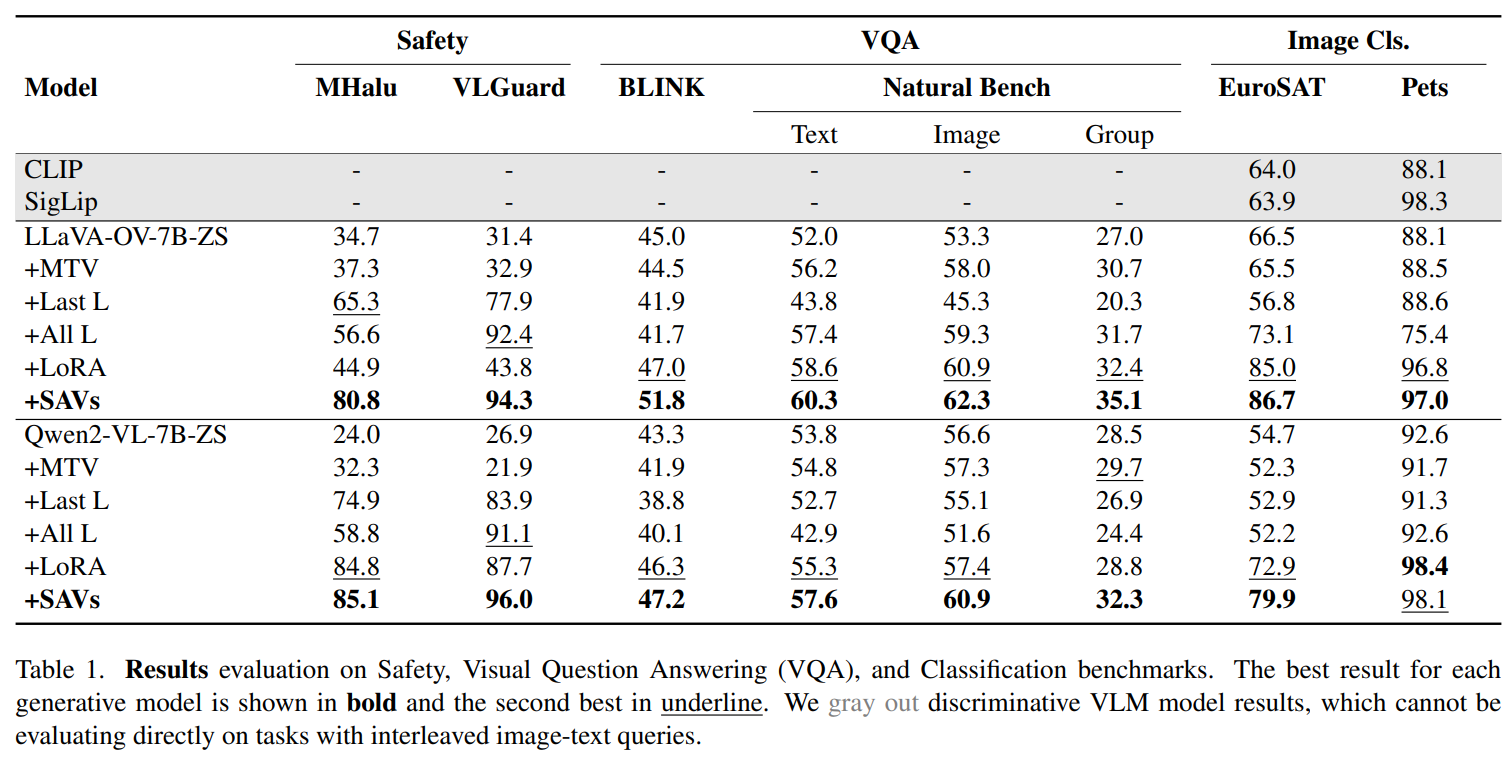
For evaluation, SAVs were tested on two state-of-the-art LMMs—LLaVA-OneVision and Qwen2-VL—and compared against multiple baselines, including zero-shot (ZS) methods, few-shot methods, and finetuning approaches like LoRA. Evaluations spanned a wide range of discriminative VL tasks. SAVs outperformed baselines in detecting hallucinations (e.g., distinguishing “hallucinating” from “not hallucinating”) and harmful content in datasets like LMM-Hallucination and VLGuard. SAVs demonstrated superior performance on challenging datasets like BLINK and NaturalBench, which require visual and compositional reasoning. SAVs were also highly effective on datasets like EuroSAT (satellite image classification) and Oxford-IIIT-Pets (fine-grained classification of pet breeds). Results showed that SAVs consistently outperformed zero-shot and few-shot baselines, closing the gap with discriminative vision-language models (VLMs) like CLIP and SigLIP. For instance, SAVs achieved higher accuracy on safety tasks and demonstrated robust performance across VQA and image classification benchmarks.
Moreover, SAVs require only a few labeled examples per class, making them practical for tasks with limited training data. The method identifies specific attention heads that contribute to classification, offering insights into the model’s inner workings. SAVs are adaptable to a variety of discriminative tasks, including those involving interleaved image-text inputs. By leveraging a sparse subset of attention heads, the method is computationally lightweight and scalable.
While SAVs provide a significant advancement, they rely on accessing the internal architecture of the LMM. This dependency limits their applicability to open-source models and poses challenges for broader usage. Additionally, tasks like image-text retrieval might benefit from finer-grained confidence metrics than the current majority voting mechanism. Future research could explore enhancing SAVs for tasks like multimodal retrieval, data compression, and feature embedding for downstream applications.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Revolutionizing Vision-Language Tasks with Sparse Attention Vectors: A Lightweight Approach to Discriminative Classification appeared first on MarkTechPost.
