

Large Language Models (LLMs) have become an indispensable part of contemporary life, shaping the future of nearly every conceivable domain. They are widely acknowledged for their impressive performance across tasks of varying complexity. However, instances have arisen where LLMs have been criticized for generating unexpected and unsafe responses. Consequently, ongoing research aims to align LLMs more closely with human preferences while fully leveraging their extensive training data.
Methods such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) have proven effective. However, they still require iterative training, which is often impractical. Researchers are therefore focusing on modifying inference approaches to match the performance of training-based optimization methods. This article explores the latest research that enhances human preference alignment during inference time.
Researchers from Shanghai AI Laboratory have introduced Test-Time Preference Optimization (TPO), a novel framework designed to align LLM outputs with human preferences during inference. This framework can be conceptualized as an online, on-policy learning paradigm, where the policy model continuously interacts with a novel reward model to refine its outputs.
TPO incorporates a mechanism to leverage interpretable textual feedback for preference optimization instead of conventional numerical scoring. To achieve this, authors translate reward signals into textual rewards through critiques. The model then generates suggestions by the transformed rewards and updates its outputs to align with the signals during testing.
During the actual test, the newly generated responses are scored at each inference-time optimization step, and the extreme ends of response quality are classified as “chosen” or “rejected” outputs. The model then learns the strength from the best or “chosen” outputs and the shortfalls of rejected responses to compile a “textual loss.” The model then generates suggestions or “ textual gradients” for the next iteration. TPO thus improves the output iteratively based on interactions with text rewards.
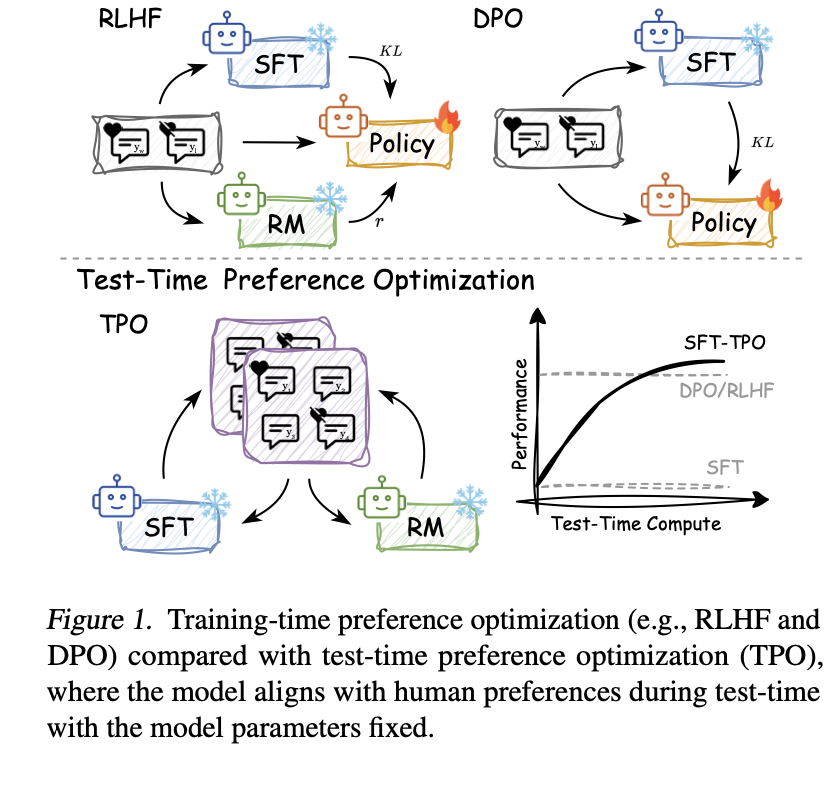
The authors used aligned and unaligned policy models to validate the concept and determine whether the model had undergone preference optimization during training. Two key models included in the study were Llama-3.1-70B-SFT, an unaligned model that did not undergo preference optimization during training, and Llama-3.1-70B-Instruct, an aligned model trained with preference optimization. Additionally, experiments spanned many datasets to evaluate instruction following, preference alignment, safety, and mathematical reasoning.
Results from these experiments confirmed that a few TPO optimization steps significantly improved performance in both aligned and unaligned models. When comparing TPO-based inference optimization with traditional training optimization approaches, researchers found that the unaligned Llama-3.1-70B-SFT model outperformed its aligned counterpart Llama-3.1-70B-Instruct after undergoing TPO epochs. Furthermore, applying TPO to an aligned model with as few as 22 billion parameters achieved an LC score of 53.4% and a WR score of 72.2%
Conclusion: The research team introduced TPO, an online, on-policy learning framework to align outputs from LLMs by human preference. This framework optimized the responses in inference time and eliminated the hassle of retraining and weight updates. Additionally, TPO offered high scalability and flexibility, making it a promising approach for future LLM works.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post Test-Time Preference Optimization: A Novel AI Framework that Optimizes LLM Outputs During Inference with an Iterative Textual Reward Policy appeared first on MarkTechPost.
