: Deep Dive into 25 Different Types of RAG")


Retrieval-augmented generation (RAG) architectures are revolutionizing how information is retrieved and processed by integrating retrieval capabilities with generative artificial intelligence. This synergy improves accuracy and ensures contextual relevance, creating systems capable of addressing highly specific user needs. Below is a detailed exploration of the 25 types of RAG architectures and their distinct applications.
Corrective RAG: Corrective RAG functions as a real-time fact-checker designed to generate responses and validate them against reliable sources to minimize errors. Its architecture includes an error-detection module that identifies and corrects discrepancies in the generated response before delivery. For instance, in healthcare, a chatbot utilizing Corrective RAG can provide dosage recommendations for medications and cross-verify these suggestions with medical guidelines. This architecture is particularly valuable in healthcare, law, and finance industries, where minor inaccuracies can have severe consequences. By ensuring responses align with trusted data, Corrective RAG prioritizes accuracy and reliability.
Speculative RAG: Speculative RAG anticipates user needs by predicting queries and preparing relevant responses ahead of time. This forward-thinking approach analyzes user context and behavior to pre-fetch data, reducing response times and enhancing user experience. For example, a news application employing Speculative RAG might detect a user’s interest in environmental issues based on their search history and proactively display trending articles on climate change. Its real-time prediction capabilities are ideal for platforms requiring instantaneous responses, such as e-commerce, customer service, and news delivery.
Agenetic RAG: Agenetic RAG offers adaptability by evolving with the user over time learning preferences through repeated interactions. Unlike static systems, Agenetic RAG dynamically refines its database and retrieval processes, creating a personalized experience. For instance, a streaming service using this architecture might identify a user’s growing preference for thriller movies and subsequently prioritize this genre in its recommendations. Its ability to self-adjust without manual intervention makes it highly effective in personalized recommendation systems, particularly retail, entertainment, and digital content curation.
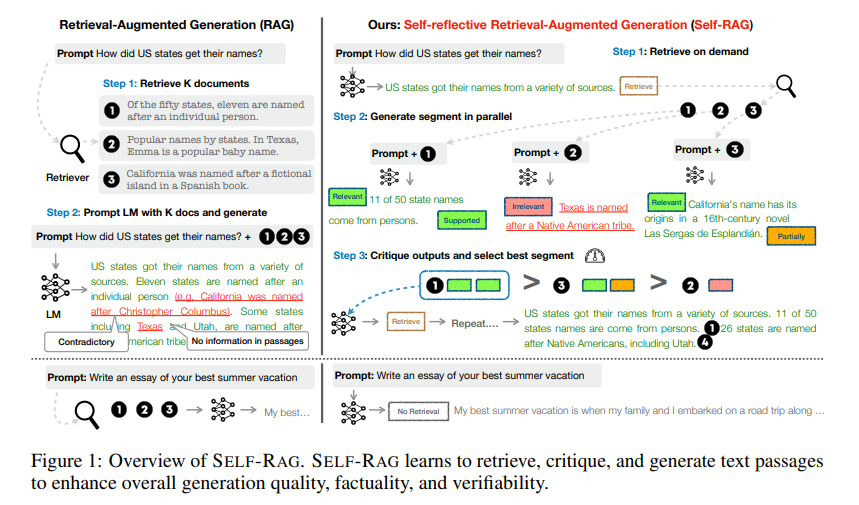
Self-RAG: Self-RAG is an autonomous architecture focused on continuous improvement. It evaluates the accuracy and relevance of its responses, iteratively refining its retrieval methods. For example, a financial analysis tool employing Self-RAG could use real-time stock market data and adjust its predictions based on historical patterns and user feedback. This self-optimization capability ensures the system remains accurate and efficient, making it invaluable in dynamic industries such as finance, weather forecasting, and logistics.
Adaptive RAG: Adaptive RAG excels at adjusting its responses based on real-time changes in user context or environmental factors. This flexibility allows it to maintain relevance even in dynamic scenarios. For instance, an airline booking system powered by Adaptive RAG might analyze seat availability in real-time and offer alternative suggestions based on fluctuating conditions, such as unexpected cancellations. Its ability to seamlessly adapt to changing circumstances makes it highly suitable for ticketing platforms, supply chain logistics, and live event management systems.
Refeed Feedback RAG: Refeed Feedback RAG improves through direct user feedback, making it a highly interactive and adaptive system. This architecture continuously refines its retrieval and generation methods by learning from corrections to better meet user expectations. For example, a telecom chatbot might initially misinterpret a user’s query but adapt over time by incorporating frequent corrections into its knowledge base. This ensures that subsequent interactions are more accurate and aligned with user preferences, making it ideal for customer service applications where satisfaction and adaptability are key.
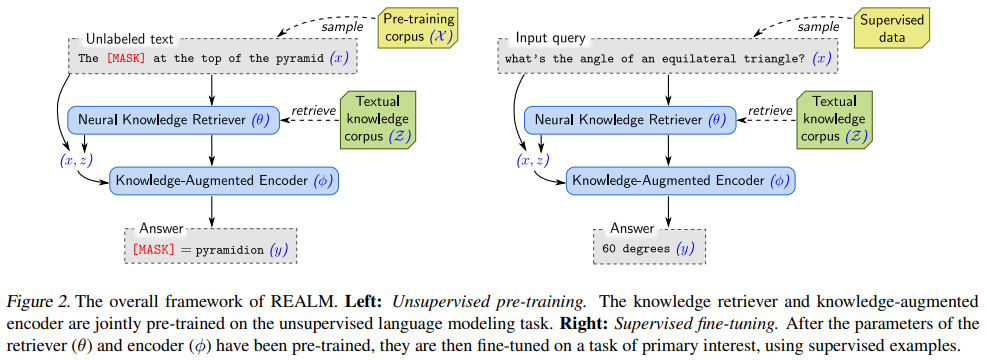
Realm RAG: Realm RAG combines the retrieval prowess of conventional systems with the deep contextual understanding of LLMs. This architecture delivers context-specific and comprehensive answers, particularly useful in highly technical or legal domains. For example, a Realm RAG legal assistant can retrieve case precedents for copyright law queries, saving significant research time while ensuring precision. By integrating LLM capabilities, Realm RAG offers unparalleled depth and contextual relevance in its responses.
Raptor RAG: Raptor RAG organizes data hierarchically, streamlining the retrieval process for complex or structured datasets. Using a tree-based organization, Raptor RAG ensures quick and precise access to the most relevant information. For instance, a hospital using this architecture could categorize patient symptoms and link them to probable diagnoses in a structured, efficient manner. This type of RAG is particularly effective in industries like healthcare, where accurate and swift diagnosis is critical, and e-commerce, where products must be categorized systematically for better user navigation.
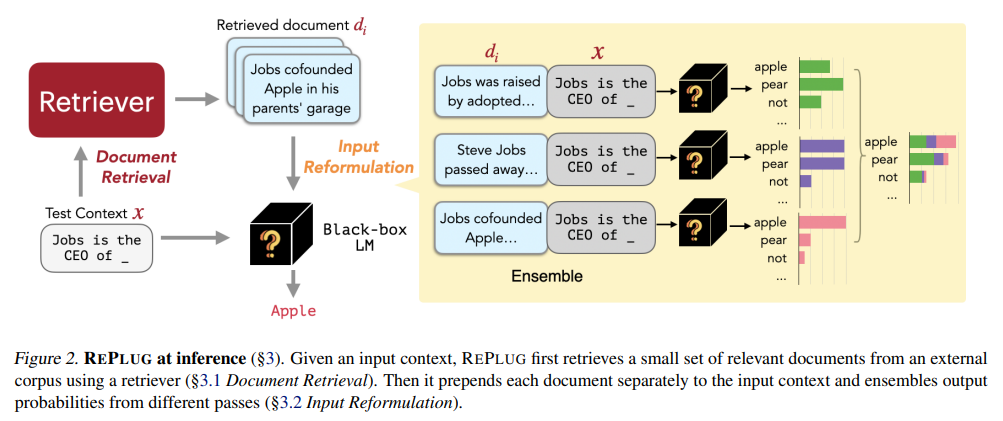
Replug RAG: Replug RAG acts as a versatile connector, integrating seamlessly with external data sources to provide real-time updates and insights. This architecture is particularly effective in applications requiring live data, such as financial or weather forecasting tools. For example, a financial platform might use Replug RAG to fetch the latest stock prices and market trends, ensuring users receive the most current information. Its ability to combine internal and external data sources enhances its relevance across a wide range of dynamic, data-intensive industries.
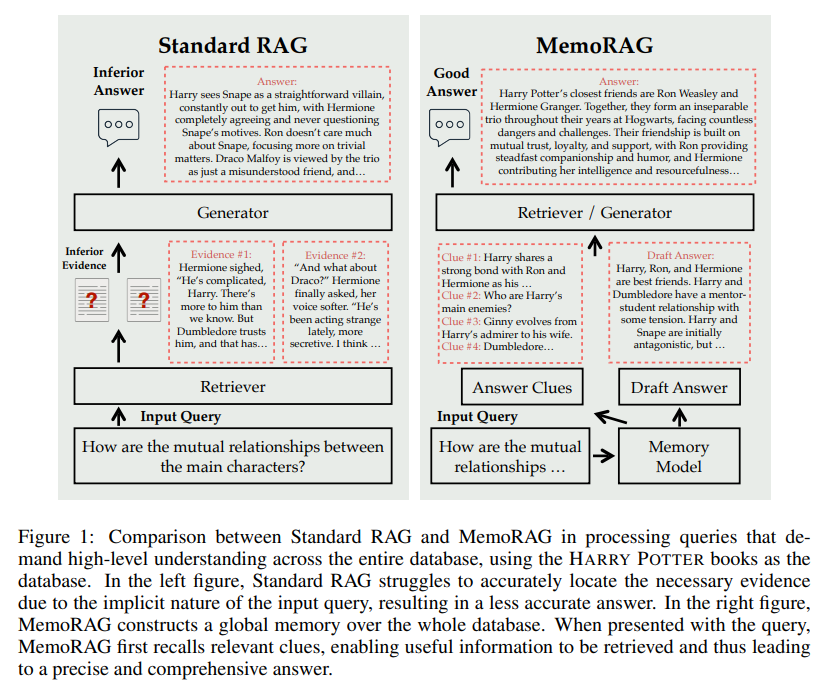
Memo RAG: Memo RAG is designed to retain context and continuity across user interactions. Unlike conventional systems that treat each query independently, Memo RAG stores and utilizes memory from previous exchanges to deliver more coherent responses. For instance, in customer service, Memo RAG allows a virtual assistant to remember a user’s earlier issues, making subsequent interactions smoother and more personal. Similarly, an educational platform using Memo RAG can recall the topics a student previously explored, tailoring lessons to reinforce prior learning. This contextual retention significantly enhances user satisfaction and engagement, making Memo RAG invaluable in tutoring systems, customer support, and personalized learning applications.
Attention-Based RAG: Attention-Based RAG emphasizes key elements of a query, filtering out irrelevant details to provide more focused and accurate responses. This architecture ensures that users receive precise information without extraneous distractions by prioritizing essential terms and context. For example, a research assistant tool can use Attention-Based RAG to identify the most relevant studies on “AI in healthcare,” avoiding unrelated articles. This approach is particularly beneficial in academia, pharmacological research, and legal queries, where specificity and accuracy are paramount. Its ability to zero in on critical aspects of a query distinguishes Attention-Based RAG as a highly efficient tool for niche domains.
RETRO RAG: RETRO RAG leverages historical context to provide informed and relevant answers. RETRO RAG offers a well-rounded perspective by incorporating past interactions, documents, or datasets into its responses. For instance, a corporate knowledge management system can use RETRO RAG to recall project decisions, helping employees understand ongoing strategies without redundancy. Similarly, this architecture assists attorneys in the legal sector by referencing relevant precedents to address complex cases. RETRO RAG’s integration of historical context ensures that responses are comprehensive and contextually rich, making it indispensable for industries prioritizing continuity and institutional knowledge.
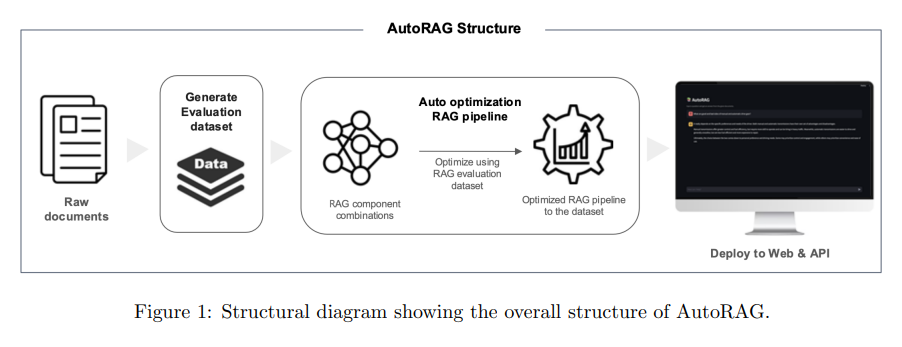
Auto RAG: Auto RAG is a hands-free, automated retrieval system with minimal human oversight. This architecture is particularly suited for environments dealing with dynamic, high-volume data. For example, a news aggregator employing Auto RAG can compile daily headlines from multiple sources, automatically ranking them by relevance and timeliness. Auto RAG continuously scans data streams and ensures users can access the most pertinent information without manual intervention. This automation significantly reduces operational workloads, making it ideal for dynamic content platforms, news delivery systems, and dashboards requiring real-time updates.
Cost-Constrained RAG: Cost-Constrained RAG optimizes retrieval within predefined budgetary limits, ensuring a balance between efficiency and cost. This architecture is especially relevant for organizations or sectors needing cost-effective solutions without compromising data accuracy. For example, a non-profit organization might use Cost-Constrained RAG to access essential data while adhering to financial constraints. This system minimizes expenditures while delivering relevant results by prioritizing resource-efficient retrieval methods. Cost-Constrained RAG is particularly valuable in education, small businesses, and resource-limited sectors that demand high performance on tight budgets.
ECO RAG: ECO RAG is an environmentally conscious architecture that minimizes energy consumption during data retrieval. With growing concerns about sustainability, ECO RAG aligns with the goals of green-tech initiatives, reducing the carbon footprint of AI systems. For example, an environmental monitoring platform might use ECO RAG to optimize energy use when retrieving data from remote sensors. By balancing performance with environmental responsibility, ECO RAG caters to organizations aiming to adopt sustainable practices. This architecture is especially important for industries that reduce ecological impact, such as renewable energy, conservation, and sustainable development projects.
Rule-Based RAG: Rule-based RAG enforces strict compliance with predefined guidelines, making it essential in heavily regulated industries. This architecture ensures that all responses adhere to legal, ethical, or organizational standards. For example, a Rule-Based RAG financial advisory platform can provide investment recommendations that comply with regional regulations. Similarly, Rule-Based RAG ensures that medical guidance adheres to established protocols in healthcare. By embedding compliance into its framework, this architecture mitigates risks associated with non-adherence, making it highly reliable for legal, financial, and healthcare applications.
Conversational RAG: Conversational RAG is tailored for interactive dialogue, enabling systems to engage users in natural, real-time conversations. Its ability to adapt responses based on the flow of dialogue ensures that interactions are seamless and engaging. For instance, a retail chatbot using Conversational RAG can respond to customer queries about product details while adapting its recommendations based on previous questions. This makes it ideal for enhancing customer experiences in e-commerce, hospitality, and virtual assistance. The dynamic conversational flow offered by this architecture fosters deeper user engagement, boosting satisfaction and loyalty.
Iterative RAG: Iterative RAG refines responses over multiple interactions, learning and improving with each iteration. This makes it a powerful tool for technical support and troubleshooting, where initial answers may require refinement. For example, a tech support bot using Iterative RAG could assist users with device setup issues by offering increasingly specific solutions based on feedback from previous interactions. Its iterative nature ensures the system evolves, delivering more accurate and effective responses. Iterative RAG’s focus on continuous improvement makes it an excellent choice for complex problem-solving and user-guided processes.
HybridAI RAG: HybridAI RAG combines the strengths of multiple machine learning models, integrating their capabilities into a single framework for comprehensive solutions. By leveraging diverse models, HybridAI RAG excels in tasks that require multifaceted analysis. For instance, predictive maintenance platforms use this architecture to analyze sensor data, logs, and environmental factors, predicting equipment failures before they occur. By incorporating varied perspectives from multiple models, HybridAI RAG delivers nuanced insights, making it invaluable for complex systems like financial modeling, healthcare diagnostics, and industrial monitoring.
Generative AI RAG: Generative AI RAG integrates retrieval mechanisms with creative content generation, offering originality alongside relevance. This architecture is particularly useful in marketing, content creation, and branding, where fresh and engaging ideas are paramount. For example, a marketing assistant powered by Generative AI RAG might generate new ad copy by analyzing past campaigns and current trends. By blending retrieval with creative outputs, this architecture supports innovative endeavors while aligning with existing guidelines and user expectations.
XAI RAG: XAI RAG emphasizes explainability, ensuring users understand how and why a response was generated. Transparency is critical in healthcare, legal services, and financial advising, where decisions must be justified. For example, in a healthcare setting, XAI RAG can recommend a treatment plan while providing detailed reasoning based on medical data. This architecture fosters trust and compliance, making it a preferred choice for regulated industries requiring clear documentation of decision-making processes.
Context Cache RAG: Context Cache RAG maintains a memory of relevant data points, enabling coherent and contextually consistent responses across multiple interactions. This architecture is particularly effective in educational tools, where continuity across lessons or topics is essential. For instance, a virtual tutor using Context Cache RAG might recall details from previous sessions to provide tailored guidance during a follow-up lesson. Its ability to retain and integrate contextual information ensures that user experiences remain seamless and productive, enhancing long-term engagement in learning platforms.
Grokking RAG: Grokking RAG focuses on deep understanding, allowing it to synthesize complex data and provide intuitive explanations. This architecture is ideal for scientific research and technical domains requiring deep comprehension. For example, a research assistant employing Grokking RAG can simplify intricate concepts in quantum mechanics, breaking them down into digestible insights for broader audiences. Its ability to grasp and convey nuanced topics makes it valuable for knowledge dissemination and collaborative research.
Replug Retrieval Feedback RAG: Replug Retrieval Feedback RAG refines its connections to external data sources through continuous feedback, enhancing accuracy and relevance. This architecture excels in data-heavy applications where real-time access and precision are crucial. For instance, a market insights platform might use Replug Retrieval Feedback RAG to retrieve financial data from multiple sources, adjusting its algorithms based on user input. By dynamically optimizing its retrieval process, this architecture ensures that outputs remain precise and relevant, catering to finance, logistics, and public data analysis.
Attention Unet RAG: Attention Unet RAG specializes in segmenting data at a granular level, making it indispensable for applications requiring detailed analysis. This architecture is particularly effective in medical imaging and geospatial analysis, where precision is critical. For example, an Attention Unet RAG radiology assistant can analyze MRI scans, segmenting tissues and structures for enhanced diagnosis. Its ability to process and present fine details sets it apart as a tool for advanced analytical tasks, such as satellite imaging and material inspection.
Conclusion
From multi-model integration to explainability and deep understanding, these architectures demonstrate the transformative potential of RAG in tackling specific challenges. Organizations can harness the full power of AI-driven retrieval and generation to optimize processes, enhance user experiences, and drive innovation across sectors by selecting the appropriate RAG type for a given application. This comprehensive analysis of all 25 RAG architectures highlights their unique strengths and offers a roadmap for leveraging them effectively in various industries. Together, they represent the future of intelligent systems, where precision, adaptability, and creativity converge.
Sources:
- https://medium.com/@rupeshit/mastering-the-25-types-of-rag-architectures-when-and-how-to-use-each-one-2ca0e4b944d7
- https://www.linkedin.com/posts/bhavishya-pandit_25-types-of-rag-ugcPost-7261595005167796224-FjXW/
- https://arxiv.org/html/2401.15884v2
- https://arxiv.org/pdf/2310.11511
- https://arxiv.org/pdf/2409.05591
- https://arxiv.org/pdf/2002.08909
- https://arxiv.org/pdf/2410.20878
- https://arxiv.org/pdf/2301.12652
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Retrieval-Augmented Generation (RAG): Deep Dive into 25 Different Types of RAG appeared first on MarkTechPost.
