

LLMs based on transformer architectures, such as GPT and LLaMA series, have excelled in NLP tasks due to their extensive parameterization and large training datasets. However, research indicates that not all learned parameters are necessary to retain performance, prompting the development of post-training compression techniques to enhance efficiency without significantly reducing inference quality. For example, the LASER model uses singular value decomposition (SVD) to compress feedforward network (FFN) weight matrices by removing factors with minimal singular values, reducing weight noise from training. However, LASER only targets individual weight matrices, limiting its ability to utilize shared information between them.
Researchers at Imperial College London introduced a novel framework to enhance the reasoning abilities of LLMs by compressing the Multi-Head Attention (MHA) block through multi-head tensorisation and Tucker decomposition. This approach enforces a shared higher-dimensional subspace across attention heads, enabling structured denoising and compression, with compression rates reaching up to 250x without requiring additional data or fine-tuning. Unlike existing methods focused on FFN weights, this method addresses MHA limitations by leveraging domain knowledge about attention heads’ shared and specialized roles. Extensive tests on benchmark datasets demonstrated improved reasoning in both encoder and decoder architectures, alongside compatibility with FFN-based techniques.
The study adopts mathematical notations commonly used in previous works, with scalars, vectors, matrices, and tensors represented as a and A, respectively. Operations such as matrix transpose, Frobenius norm, and tensor mode-n product are defined for computational tasks. Tensors, which are multidimensional arrays, extend from simple scalars (0D) to higher dimensions by stacking lower-dimensional structures. The mode-n product links a tensor and a matrix along a specific dimension. SVD decomposes matrices into rank-1 components, enabling noise reduction through low-rank approximations by discarding insignificant values. Tucker decomposition extends SVD to tensors, breaking them into smaller core tensors and factor matrices, which aids in efficient data representation and dimensionality reduction.
The study proposes a method to reshape MHA weight matrices in transformers into 3D tensors instead of the conventional 2D format. Tucker decomposition composes these tensors into core tensors and shared factor matrices across all attention heads within a transformer layer. This technique ensures that attention heads function within the same subspace, improving reasoning capabilities and reducing noise. Compared to existing methods such as LASER and TRAWL, this approach leverages shared low-rank structures to enhance performance and efficiency while reducing the number of parameters.
Extensive experiments validated the proposed framework on four benchmark reasoning datasets using three LLMs: RoBERTa, GPT-J, and LLaMA2, encompassing both encoder-only and decoder-only architectures. The framework, applied selectively to transformer layers, significantly enhanced reasoning abilities while achieving parameter compression. Results showed compatibility with FFN-only compression methods like LASER, achieving improved accuracy and loss reduction. A hybrid approach combining LASER and the proposed method usually yielded the best performance. Ablation studies confirmed the effectiveness of compressing all MHA weights together, outperforming separate compression of query, key, value, and output weights, further validating the framework’s design.
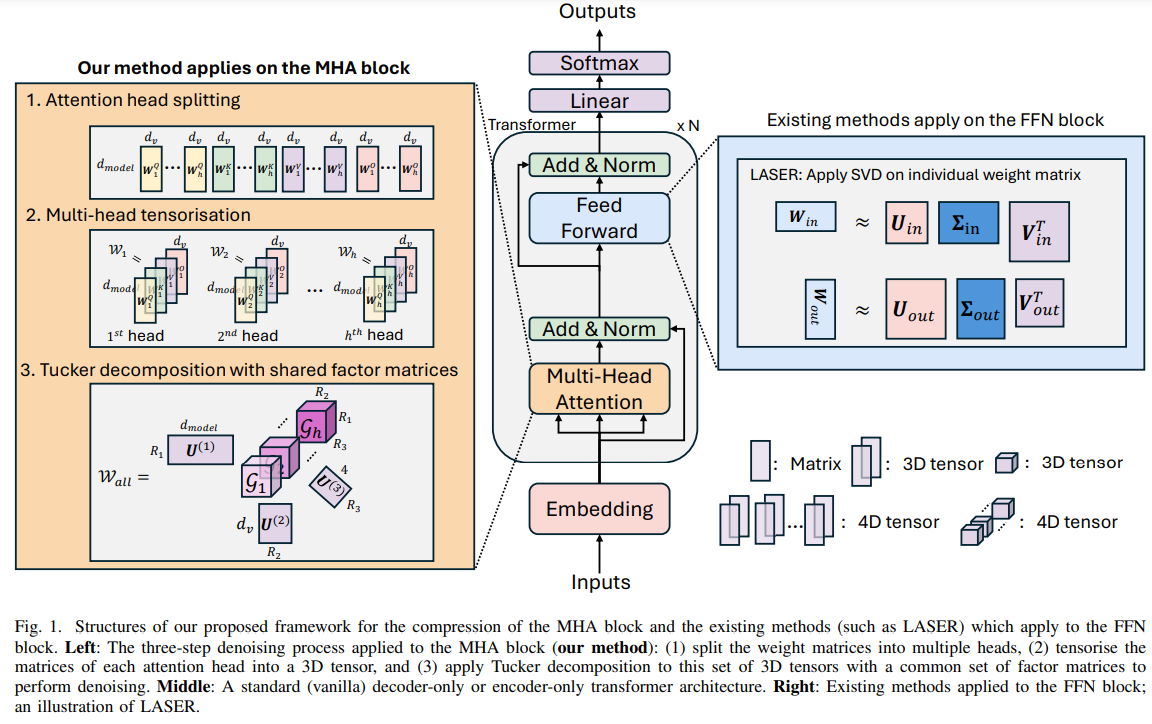
In conclusion, the study introduced a framework to enhance reasoning in LLMs while achieving significant parameter compression. By leveraging domain knowledge about MHA and employing a unique multi-head tensorisation with Tucker decomposition, we denoise MHA weights and encode diverse information within a shared higher-dimensional subspace. This approach improves reasoning in encoder-only and decoder-only LLMs with up to 250x compression, requiring no additional training or fine-tuning. The method can also complement FFN-based denoising techniques for further gains. While hyperparameter tuning varies across datasets, future work will focus on developing generalizable settings for broader applicability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.

The post TensorLLM: Enhancing Reasoning and Efficiency in Large Language Models through Multi-Head Attention Compression and Tensorisation appeared first on MarkTechPost.
